
Ce que tu vas apprendre
Agréger en SQL
Laisser PostgreSQL faire la somme avec _read_group au lieu de charger
puis additionner des milliers de lignes en Python.
Écrire en flux
Activer constant_memory pour que chaque ligne parte sur le disque
aussitôt écrite, et garder une RAM plate.
Mesurer le gain
Comparer l'approche SQL et l'approche « tout charger » sur un vrai volume, chiffres à l'appui.
sale. Notions utiles : domaines de recherche et
agrégats SQL.
Le piège du « tout charger »
Les articles précédents itéraient sur un recordset : for order in self, puis
for line in order.order_line. Parfait pour une poignée de commandes
sélectionnées. Catastrophique pour synthétiser tout le carnet de ventes :
charger 200 000 lignes en mémoire pour les additionner en Python, c'est 200 000 objets
instanciés, autant d'accès aux champs, et un pic de RAM proportionnel au volume.
La règle d'or des rapports volumineux : ne jamais charger ce qu'on peut agréger.
PostgreSQL sait sommer des millions de lignes en une requête ; autant le laisser faire. Côté
écriture, xlsxwriter sait sérialiser le classeur au fil de l'eau plutôt que de
le garder entier en mémoire. On combine les deux dans une méthode
_build_sales_xlsx_bulk.
1. Agréger en SQL avec _read_group
En Odoo 19, _read_group(domain, groupby, aggregates) traduit l'agrégation en
une requête SQL GROUP BY et ne ramène que les valeurs calculées — aucun
enregistrement n'est instancié pour le calcul. On l'appelle deux fois : par produit et par
mois.
@api.model
def _bulk_summary_data(self):
"""Agrège tout le carnet de ventes confirmées en SQL, sans charger les lignes."""
line_domain = [('display_type', '=', False),
('order_id.state', 'in', ('sale', 'done'))]
product_groups = self.env['sale.order.line']._read_group(
line_domain,
groupby=['product_id'],
aggregates=['price_subtotal:sum', '__count'],
)
products = sorted(
((product.display_name, count, subtotal)
for product, subtotal, count in product_groups),
key=lambda r: r[2], reverse=True,
)
order_domain = [('state', 'in', ('sale', 'done'))]
month_groups = self.env['sale.order']._read_group(
order_domain,
groupby=['date_order:month'],
aggregates=['amount_untaxed:sum', '__count'],
)
months = [
((period.strftime('%m/%Y') if period else _('Inconnu')), count, untaxed)
for period, untaxed, count in month_groups
]
return products, monthsTrois points méritent l'attention :
| Élément | Comportement |
|---|---|
'price_subtotal:sum' | agrégat SUM calculé par PostgreSQL. |
'__count' | jeton spécial : ajoute le COUNT du groupe. |
'date_order:month' | granularité temporelle ; la valeur du groupe est un datetime au 1er du mois. |
Pour un groupby sur un champ relationnel, la valeur remontée est un
recordset (ici un product.product) déjà préchargé : on lit son
display_name sans requête supplémentaire. Le résultat tient en quelques
dizaines de tuples, quel que soit le nombre de lignes sous-jacentes.
2. Écrire en flux avec constant_memory
Par défaut, xlsxwriter garde tout le classeur en mémoire jusqu'au
close(). L'option constant_memory renverse la logique : chaque
ligne est écrite sur le disque dès qu'elle est terminée, puis oubliée. L'empreinte RAM
reste plate, à un détail près — il faut écrire les cellules ligne par ligne, dans
l'ordre croissant, sans jamais revenir en arrière.
import xlsxwriter # vendored par Odoo
products, months = self._bulk_summary_data()
buffer = io.BytesIO()
workbook = xlsxwriter.Workbook(
buffer, {'in_memory': True, 'constant_memory': True})Chaque feuille de synthèse est ensuite écrite de haut en bas : largeurs de colonnes posées avant les lignes, puis titre, en-tête, lignes agrégées et total.
def _write_summary(self, workbook, sheet_name, title, label, rows, ...):
"""Écrit une feuille de synthèse en flux (cellules en ordre croissant)."""
sheet = workbook.add_worksheet(sheet_name)
# Largeurs définies avant l'écriture des lignes (contrainte du flux).
sheet.set_column(0, 0, 42)
sheet.set_column(1, 1, 12)
sheet.set_column(2, 2, 18)
# merge_range reste possible ici car la ligne 0 est écrite en premier,
# avant toute autre ligne (contrainte du mode flux).
sheet.merge_range(0, 0, 0, 2, title, title_fmt)
sheet.set_row(0, 22)
sheet.write(1, 0, label, header_fmt)
sheet.write(1, 1, _('Nombre'), header_fmt)
sheet.write(1, 2, _('CA HT'), header_fmt)
row = 2
total_amount = 0.0
total_count = 0
for name, count, amount in rows:
sheet.write(row, 0, name, text_fmt)
sheet.write_number(row, 1, count, int_fmt)
sheet.write_number(row, 2, amount, money_fmt)
total_amount += amount
total_count += count
row += 1
sheet.write(row, 0, _('Total'), total_lbl_fmt)
sheet.write_number(row, 1, total_count, total_lbl_fmt)
sheet.write_number(row, 2, total_amount, total_money_fmt)Le merge_range du titre fonctionne malgré le mode flux parce qu'il porte sur la
ligne 0, écrite avant toute autre. Toute fusion sur une ligne déjà dépassée lèverait une
erreur : en flux, on n'écrit jamais vers le passé.
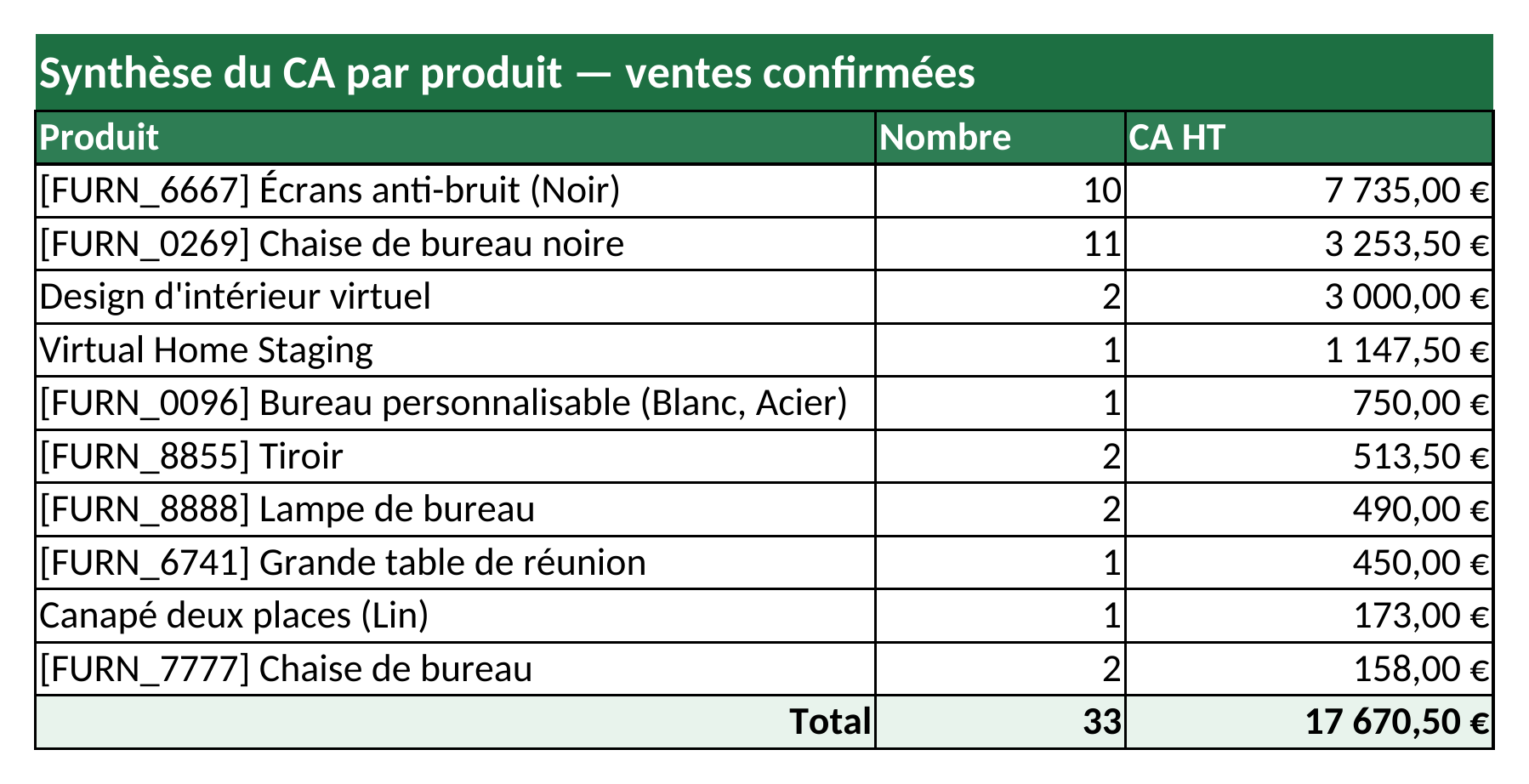
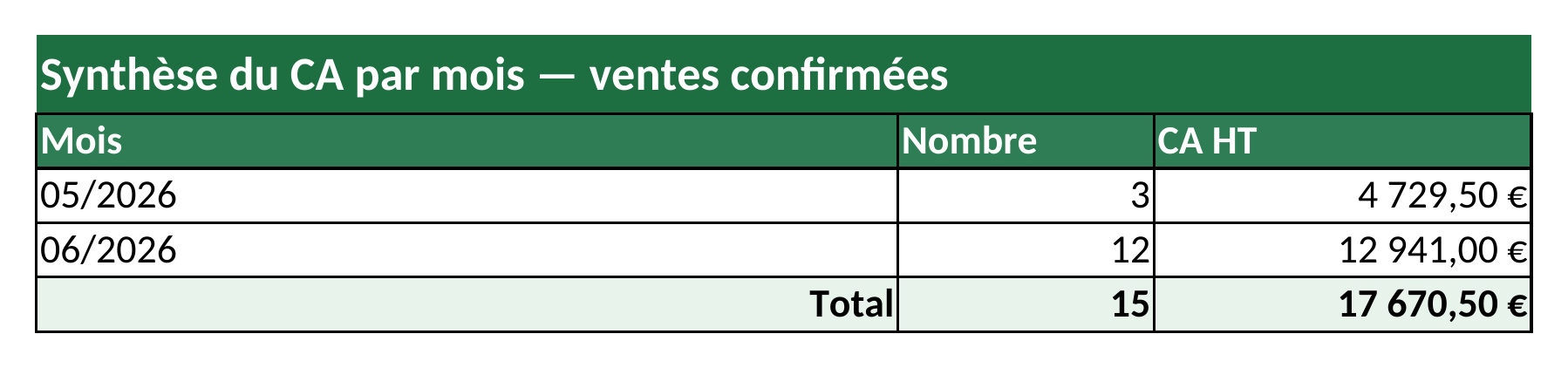
date_order:month.3. Mesurer le gain
Les grands principes méritent des chiffres. On compare, sur un même jeu de données, l'agrégation SQL et l'approche « charger puis sommer en Python ».
import time
SOL = env['sale.order.line']
line_domain = [('display_type', '=', False),
('order_id.state', 'in', ('sale', 'done'))]
n = SOL.search_count(line_domain)
# (a) Agrégation SQL : PostgreSQL fait la somme
t0 = time.perf_counter()
for _ in range(20):
groups = SOL._read_group(line_domain, ['product_id'], ['price_subtotal:sum'])
t_sql = (time.perf_counter() - t0) / 20
# (b) Tout charger puis sommer en Python
t0 = time.perf_counter()
for _ in range(3):
acc = {}
for line in SOL.search(line_domain):
acc[line.product_id.id] = acc.get(line.product_id.id, 0.0) + line.price_subtotal
t_py = (time.perf_counter() - t0) / 3
print("lignes=%d sql=%.1fms python=%.0fms speedup=%.0fx"
% (n, t_sql * 1000, t_py * 1000, t_py / t_sql))Sur un jeu de 21 033 lignes, la sortie est sans appel :
lignes=21033 sql=25.0ms python=214ms speedup=9xNeuf fois plus rapide — et l'écart se creuse avec le volume, car l'approche Python paie un
coût mémoire et CPU linéaire, là où le GROUP BY reste optimisé par l'index.
Surtout, l'agrégation SQL garde une empreinte mémoire constante : elle ne ramène que les
quelques lignes de groupe, jamais les 21 033 enregistrements.
Le controller et le bouton
Le rapport ne dépend pas d'une sélection : il synthétise tout le carnet. Le controller appelle donc directement la méthode sur le modèle, sans identifiants.
@route('/odooskills/export/sales/xlsx_bulk', type='http', auth='user', readonly=True)
def export_sales_xlsx_bulk(self, **kw):
content = request.env['sale.order']._build_sales_xlsx_bulk()
headers = [
('Content-Type',
'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet'),
('Content-Disposition', content_disposition('rapport_ventes_synthese.xlsx')),
]
return request.make_response(content, headers)
⚠️ Pièges à éviter
- Charger un grand recordset puis sommer en Python fait exploser la RAM : préférer
_read_groupqui agrège côté base. - En mode
constant_memory, écrire les cellules dans l'ordre croissant des lignes ; revenir vers une ligne déjà écrite lève une erreur. - Définir les largeurs de colonnes avant d'écrire les données, et n'utiliser
merge_rangeque sur la ligne courante (ici la ligne de titre). - Le jeton
'__count'compte les enregistrements du groupe sans champ dédié ; ne pas le confondre avec un agrégat de champ. - La valeur d'un
groupbyen:monthest undatetime(1er du mois), à formater — pas une chaîne toute prête.
À retenir
_read_group(domain, groupby, aggregates)agrège en SQL et ne ramène que les valeurs calculées — la seule voie tenable sur gros volumes.constant_memorysérialise le classeur au fil de l'eau : RAM plate, au prix d'une écriture strictement ordonnée.- Mesuré sur 21 033 lignes : agrégation SQL 9× plus rapide que le « tout charger », et à empreinte mémoire constante.
Télécharge le Guide Technique Odoo
Un module Odoo 19 fonctionnel, 20+ articles techniques, environnements de dev et pipeline complet — le tout en PDF.
Télécharger le guide📘 Pour aller plus loin : nos formations Odoo 19


À lire également
- Insérer des graphiques dans un rapport Excel — l'article précédent, où l'agrégation se faisait encore en Python.
- Générer un rapport Excel natif dans Odoo 19 — le point de départ de la série.
- Écrire des tests automatisés en Odoo 19 — pour figer le résultat d'une agrégation par un test.