
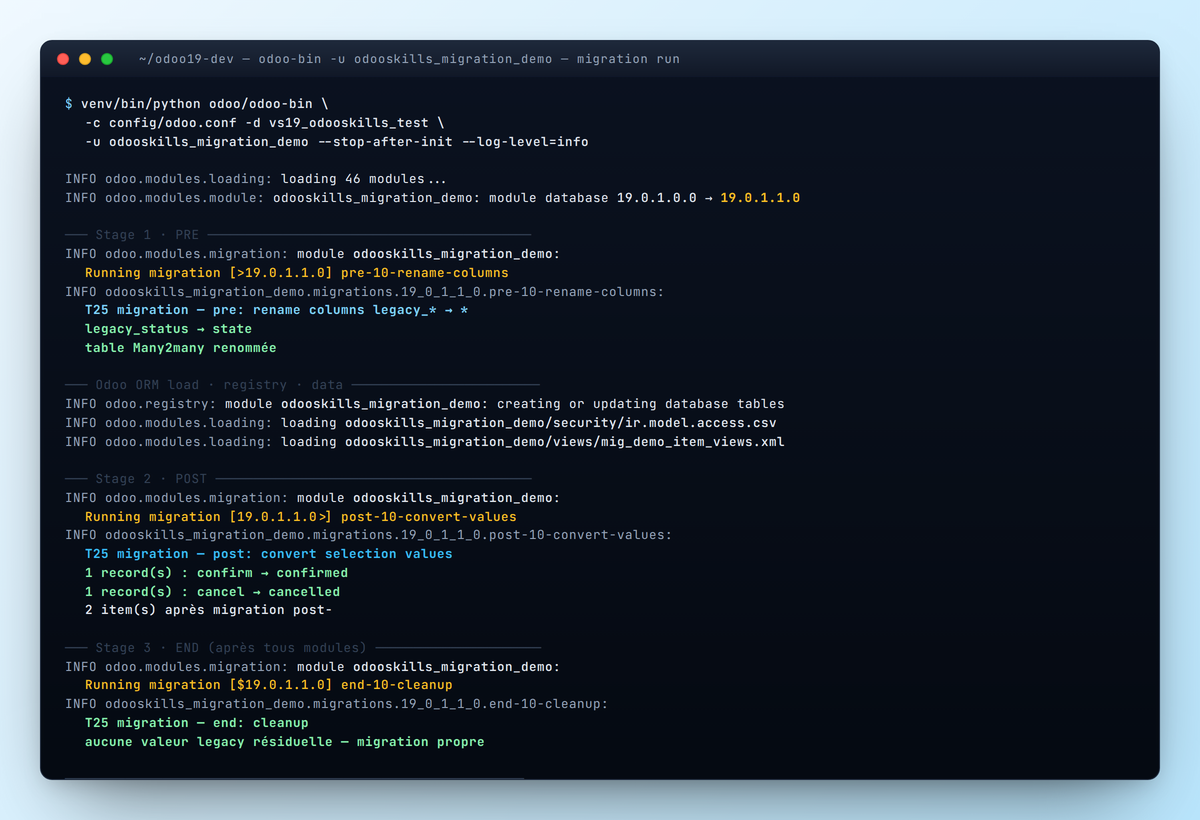
[>19.0.1.1.0] pre, [19.0.1.1.0>] post,
[$19.0.1.1.0] end. Chaque stage renomme des colonnes, convertit des
valeurs selection, nettoie. Zéro perte de données.Ce que tu vas apprendre
Les 3 hooks manifest
pre_init_hook, post_init_hook, uninstall_hook — quand chacun s'exécute.
L'arborescence migrations/
Pattern migrations/<version>/{pre,post,end}-*.py et ordre d'exécution.
Signature v19 stricte
migrate(cr, version) — Odoo 19 valide le nom exact des params.
7 breaking changes
attrs, tree, _sql_constraints, champs renommés… que le code doit gérer.
Prérequis
- Odoo 19 installé (T01 Ubuntu).
- Un module Odoo 18 fonctionnel à migrer — ou le module démo qu'on va construire dans cet article.
- Base PostgreSQL de test dédiée (jamais la prod — règle numéro un d'une migration).
- Familiarité avec le manifeste Odoo, les modèles et les tests automatisés (T24) — la migration n'est sérieuse que si une suite de tests la valide.
1. Pourquoi des scripts de migration ?
Quand tu bumpes la version de ton module dans le manifest, Odoo détecte l'écart entre la version en base et la version déclarée. Il applique automatiquement les changements de schéma triviaux (ajout de colonne, création de table, index). Mais il ne sait pas comment migrer les données existantes :
- Un champ renommé (
legacy_status→state) : l'ORM va créer la nouvelle colonne et ignorer l'ancienne. Les données sont perdues. - Une valeur de selection renommée (
'confirm'→'confirmed') : les lignes gardent l'ancienne valeur, invalide pour le nouveau modèle. - Une contrainte ou une méthode de calcul modifiée : aucune donnée à migrer, mais il faut forcer un recompute.
C'est exactement le rôle des scripts de migration. Ils s'insèrent dans le cycle d'upgrade à trois moments précis :

pre → post → end
encadrent le chargement ORM. En bas, les signatures exactes des scripts de
migration et des hooks du manifest (attention à l'asymétrie).2. Les 3 hooks du manifest
Différents des scripts de migration (versionnés), les hooks du manifest s'exécutent à des moments fixes du cycle de vie du module :
# __manifest__.py
{
'name': 'Mon module',
'version': '19.0.1.0.0',
'depends': ['base'],
'data': ['...'],
'pre_init_hook': 'my_pre_init_function', # fonction dans __init__.py
'post_init_hook': 'my_post_init_function', # id.
'uninstall_hook': 'my_uninstall_function', # id.
}Dans __init__.py, tu définis ces fonctions avec une signature
légèrement différente des scripts : elles reçoivent
env directement, pas cr.
# __init__.py
def my_pre_init_function(env):
"""Exécuté AVANT registry.load() — à l'installation uniquement."""
# À ce stade les modèles ne sont pas encore chargés.
# Tu as env, mais les modèles métier de ce module ne sont pas accessibles.
env.cr.execute("CREATE INDEX IF NOT EXISTS ...")
def my_post_init_function(env):
"""Exécuté APRÈS load_data() et translations — à l'installation uniquement."""
# Tous les modèles sont chargés, tu peux écrire des records.
env['res.config.settings'].create({...})
def my_uninstall_function(env):
"""Exécuté à la désinstallation du module."""
env.cr.execute("DROP INDEX IF EXISTS ...")Attention : ces hooks ne s'exécutent qu'à l'installation (ou à la désinstallation pour le dernier). Ils ne tournent pas lors d'un simple upgrade. Pour migrer entre deux versions, utilise les scripts versionnés décrits ci-dessous.
3. L'arborescence migrations/
Odoo scanne automatiquement le dossier migrations/ à la racine du module
pour y chercher des scripts Python par version.
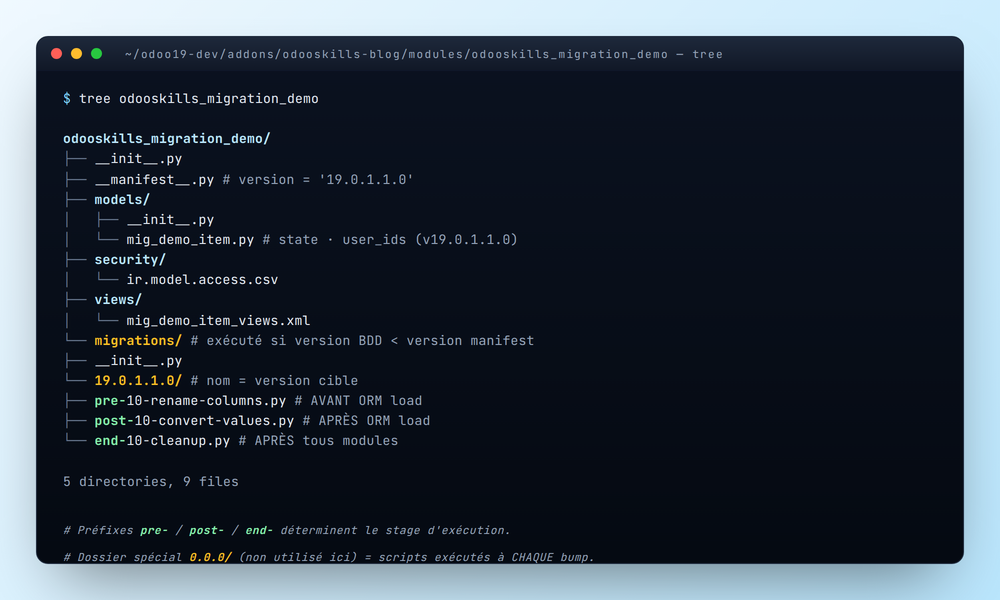
migrations/19.0.1.1.0/
contient les scripts qui s'exécutent quand Odoo détecte une base à
19.0.1.0.0 et un manifest à 19.0.1.1.0. Les préfixes
pre- / post- / end- déterminent le stage.Trois règles à connaître :
- Le nom du dossier = la version cible. Pas la version source.
Un dossier
migrations/19.0.1.1.0/s'exécute pour toute base à une version strictement inférieure. - Tri alphabétique au sein d'un stage. Préfixe tes fichiers
pre-10-...,pre-20-...pour forcer l'ordre. - Dossier spécial
0.0.0/— scripts exécutés à chaque bump de version, quelle que soit la cible. Utile pour des cleanups récurrents, mais délicat à garder idempotent.
4. Le stage pre — avant l'ORM
Le stage pre s'exécute avant que l'ORM ne charge le modèle.
C'est ta seule chance de modifier le schéma SQL avant qu'Odoo décide de créer des
colonnes neuves (et d'abandonner les anciennes).
Cas typique : tu as renommé legacy_status en state dans
ton modèle Python. Si tu ne fais rien, l'ORM va créer une colonne state
vide à côté de legacy_status. Avec un pre-*.py, tu renommes
la colonne SQL avant que l'ORM la voie :
# migrations/19.0.1.1.0/pre-10-rename-columns.py
"""Pre-migration 19.0.1.0.0 → 19.0.1.1.0 — rename SQL columns."""
import logging
_logger = logging.getLogger(__name__)
def migrate(cr, version):
_logger.info("T25 migration — pre: rename columns legacy_* → *")
# 1. Renommer la colonne selection
cr.execute("""
SELECT column_name FROM information_schema.columns
WHERE table_name = 'mig_demo_item' AND column_name = 'legacy_status'
""")
if cr.fetchone():
cr.execute("ALTER TABLE mig_demo_item RENAME COLUMN legacy_status TO state")
_logger.info(" legacy_status → state")
# 2. Renommer la table de liaison Many2many
cr.execute("""
SELECT table_name FROM information_schema.tables
WHERE table_name = 'mig_demo_item_legacy_user_rel'
""")
if cr.fetchone():
cr.execute(
"ALTER TABLE mig_demo_item_legacy_user_rel "
"RENAME TO mig_demo_item_res_users_rel"
)
_logger.info(" table Many2many renommée")Trois détails à retenir :
- Idempotent toujours : on vérifie d'abord que la vieille colonne existe avant de renommer. Un upgrade peut être relancé plusieurs fois après une interruption — le script doit tolérer ça.
- Pas d'ORM ici : le modèle n'est pas encore chargé. Tu es
en SQL pur via
cr.execute(). - Les tables Many2many se renomment aussi. Odoo nomme les tables
de liaison
<model>_<target>_rel— si tu renommes le champ, la convention change.
5. Le stage post — après l'ORM
Après le stage pre, Odoo charge les modèles, met à jour le schéma,
installe les data XML. À ce stade l'ORM est complètement disponible —
c'est le moment idéal pour convertir les données.
# migrations/19.0.1.1.0/post-10-convert-values.py
"""Post-migration 19.0.1.0.0 → 19.0.1.1.0 — convertir valeurs selection."""
import logging
from odoo import SUPERUSER_ID, api
_logger = logging.getLogger(__name__)
def migrate(cr, version):
_logger.info("T25 migration — post: convert selection values")
mapping = {'confirm': 'confirmed', 'cancel': 'cancelled'}
for old, new in mapping.items():
cr.execute(
"UPDATE mig_demo_item SET state = %s WHERE state = %s",
(new, old),
)
count = cr.rowcount
if count:
_logger.info(" %d record(s) : %s → %s", count, old, new)
# Exemple d'accès à l'ORM via env (utile si on doit invoquer un compute
# ou déclencher un recompute sur les enregistrements migrés)
env = api.Environment(cr, SUPERUSER_ID, {})
items = env['mig.demo.item'].search([])
_logger.info(" %d item(s) après migration post-", len(items))Ce qu'il faut retenir :
- La signature est identique au
pre:migrate(cr, version). Tu reçois un cursor, pas un env. - Pour obtenir un env, tu le construis avec
api.Environment(cr, SUPERUSER_ID, {}). C'est le pont vers l'ORM complet, avec les contraintes qui s'appliquent correctement. - Le SQL direct reste préférable pour les UPDATE massifs.
Passer par l'ORM pour 50 000 lignes déclenche 50 000 tracking messages si le
champ est
tracking=True. Lecr.execute()reste la bonne approche pour les conversions de masse.
6. Le stage end — une fois tous les modules chargés
Le stage end s'exécute après que tous les modules (pas
seulement le tien) soient passés par leurs pre + post. Utile pour des opérations
qui dépendent d'autres modules ou pour des validations finales.
# migrations/19.0.1.1.0/end-10-cleanup.py
"""End-migration 19.0.1.0.0 → 19.0.1.1.0 — cleanup."""
import logging
_logger = logging.getLogger(__name__)
def migrate(cr, version):
_logger.info("T25 migration — end: cleanup")
# S'assurer qu'aucune vieille valeur n'a échappé à la conversion post-
cr.execute(
"SELECT COUNT(*) FROM mig_demo_item WHERE state IN ('confirm', 'cancel')"
)
stale = cr.fetchone()[0]
if stale:
_logger.warning(
" %d records ont encore une valeur legacy — intervention manuelle",
stale,
)
else:
_logger.info(" aucune valeur legacy résiduelle — migration propre")Trois usages canoniques du stage end :
- Validations post-migration : scanner les tables pour détecter une donnée qui aurait échappé à la conversion — comme ici.
- Déclenchement de crons ou d'actions serveur qui nécessitent que tous les modules soient chargés (triggers cross-module).
- Invalidation de caches : forcer un recompute global via
env.invalidate_all()après d'importantes modifications de données.
7. Les 7 breaking changes v18 → v19 à gérer dans le code
Voici les sept changements que tout module qui passe de v18 à v19 doit traiter. Certains sont des modifications de code pure (syntaxe XML, décorateurs) ; d'autres nécessitent un script de migration pour les données.
| # | Breaking change | Impact | Action |
|---|---|---|---|
| 1 | attrs="{'invisible': [...]}" → invisible="expr" |
XML views refusées à l'install | Code — search/replace + expressions Python (==, in, and) |
| 2 | <field name="view_mode">tree,form</field> → list,form |
Actions window cassées | Code — grep tree, → list, |
| 3 | _sql_constraints = [...] → _name = models.Constraint(...) |
Contraintes SQL non appliquées | Code — attribut de classe préfixé _ |
| 4 | _constraints = [...] supprimé |
Validations Python muettes | Code — convertir vers @api.constrains |
| 5 | t-esc="val" → t-out="val" (QWeb) |
Déprécié, à migrer | Code — rename systématique |
| 6 | Champs renommés (groups_id→group_ids, product_uom→product_uom_id, tax_id→tax_ids…) |
FK cassées, compute en erreur | Script pre- SQL RENAME COLUMN |
| 7 | read_group() → _read_group() (ou formatted_read_group()) |
API interne renommée ; appels cassés en v19 | Code — renommage des appels, adapter la signature de retour |
Pour les cas 1 à 5 et 7, ce sont des corrections de code — pas besoin de script de migration. Un grep bien ciblé + un test complet suffit. C'est la suite de tests qui validera que rien n'a cassé.
Note héritage : les décorateurs @api.multi,
@api.one, @api.returns sont supprimés depuis la v13 — tu
les rencontreras dans des bases legacy v17/v18 mais pas dans un code v18
raisonnablement à jour. Pas un breaking change v18→v19 à proprement parler, mais
un audit à faire systématiquement.
Pour le cas 6, il faut un script pre- qui renomme les
colonnes SQL. Le pattern est exactement celui montré en section 4 — sur le modèle
concerné, ALTER TABLE <table> RENAME COLUMN <ancien> TO <nouveau>.
8. Pièges à éviter
⚠️ 5 pièges qui coûtent cher en production
- Signature stricte
migrate(cr, version). Odoo 19 valide les noms exacts des paramètres viaVALID_MIGRATE_PARAMS. Les seules combinaisons autorisées sont(cr, version),(cr, _version),(_cr, version),(_cr, _version). Écriremigrate(cr, installed_version)lèveTypeErrorimmédiatement. Surprenant mais strict (odoo/modules/migration.py:250-257). - Asymétrie scripts vs hooks. Les scripts versionnés
reçoivent
cr. Les hookspre_init_hook/post_init_hookreçoiventenv. Piège classique quand tu migres un morceau de hook en script versionné. - Toujours idempotent. Une migration peut être relancée après une interruption (coupure réseau, kill du process). Chaque script doit vérifier l'état avant d'agir — SELECT before ALTER, pas ALTER aveuglément.
- Dossier
0.0.0/dangereux. Les scripts qui y vivent tournent à chaque bump de version — utilisés pour des cleanups récurrents. Mais une non-idempotence à cet endroit multiplie les problèmes. - L'ORM ne connaît pas tes renames. Sans script
pre, l'ORM crée la colonne neuve et abandonne l'ancienne. Les données ne sont pas perdues — la colonne reste en base — mais elles deviennent inaccessibles via l'API. Seul un DBA avec un accès direct peut les récupérer.
Dernier point, moins un piège qu'une discipline : écris des tests qui
valident la migration. Un test TransactionCase
(T24) qui
crée des records avec les anciennes valeurs, simule le bump de version, et vérifie
que les données sont correctement converties. Sans test, une migration est une
roulette russe le jour du déploiement.
À retenir
- Trois stages encadrent le chargement ORM :
pre(SQL avant l'ORM),post(données après l'ORM),end(une fois tous les modules chargés). - Arborescence :
migrations/<version-cible>/avec préfixespre-,post-,end-. Tri alphabétique au sein d'un stage — numérotepre-10,pre-20. - Signature stricte v19 :
migrate(cr, version)— noms exacts validés, pas de synonymes. - Scripts reçoivent
cr, hooks reçoiventenv. Pour passer de l'un à l'autre :api.Environment(cr, SUPERUSER_ID, {}). - 7 breaking changes v18 → v19 : 6 de code (
attrs,tree,_sql_constraints,_constraints,t-esc, décorateurs morts) + 1 de data (champs renommés —pre+ SQLRENAME COLUMN). - Idempotence et tests : deux disciplines non négociables pour qu'une migration passe en production sans réveiller personne à 3h du matin.
Voir aussi — Parcours Infrastructure
T01 — Installer Odoo 19 Ubuntu
Base indispensable — sans environnement Odoo 19 local, pas de migration à tester.
T03 — Installer Odoo 19 Docker
Tester une migration dans un container jetable — le pattern qu'on utilise nous-mêmes.
#90 — Sécuriser Odoo en production (SSL/VPS)
Après une migration réussie en staging, la bascule prod nécessite un environnement sécurisé.
Articles complémentaires
T12 — Contraintes & computes
Les _constraints qu'on migre en @api.constrains — article de fond sur les règles de validation.
T24 — Tests automatisés
La suite de tests qui valide qu'une migration n'a rien cassé. À écrire en même temps que les scripts.
T22 — Actions serveur & cron
Déclencher un cron après migration — pattern classique du stage end.
Télécharge le Guide Technique Odoo
Module fil rouge, 20+ articles techniques, environnements de dev complet — PDF à télécharger.
Télécharger le guide