

vs19_odooskills_test, 10 000 tickets.
Écart ~2 ms/ticket à n=1, amorti à n=100.
Ce que tu vas apprendre
Profiler sans rien installer
Utiliser odoo.tools.profiler.Profiler en context manager — collecteurs
sql et traces_async natifs, résultats persistés dans
ir.profile.
Mesurer un vrai write()
Helper bench_bulk_escalate() sur helpdesk.ticket, 3 scénarios
(push ON, push OFF, search_read 10 000) et 5 répétitions pour médiane
robuste.
Lire un EXPLAIN ANALYZE
Seq Scan vs Index Scan, Execution Time,
Planning Time — et décider si ajouter un index justifie son coût.
1. Trois outils que tout dev Odoo doit connaître
Avant de mesurer, choisir ses instruments. La série propose une tour de contrôle en trois couches — toutes natives à Odoo 19 CE ou à la stack Python+Postgres.
La trousse du profiler Odoo 19
odoo.tools.profiler.Profiler— context manager natif (source v19) avec deux collecteurs par défaut :SQLCollectorcapture chaque requête et son temps,PeriodicCollectoréchantillonne la pile Python toutes les 1 ms. Les résultats sont écrits en base dansir.profileet visualisables via Speedscope (visualisateur flamegraph open-source).EXPLAIN ANALYZE— côté PostgreSQL, lance la requête réellement et retourne le plan exécuté avec les vrais temps. Universel, zéro configuration — le seul outil qui te dit si tu es sur unSeq Scanou unIndex Scan.time.perf_counter()— stdlib, haute précision (< microseconde), monotonique. Idéal pour chronométrer un appel XML-RPC ou une boucle ORM sans jouer avec les logs.
On ne parle pas de pyinstrument, py-spy ou pg_stat_statements dans cet article : utiles, mais optionnels, et souvent absents d'un environnement VPS standard. La trousse native suffit largement pour répondre à la question qui nous intéresse : « quel est le vrai coût du pattern T27 ? ».
2. Le helper bench — une méthode, un verdict
Plutôt que d'empiler les scripts ad hoc, on ajoute une méthode côté modèle. Reproductible,
testée, paramétrable push=True|False pour comparaison A/B propre.
# addons/odooskills_helpdesk/models/helpdesk_ticket.py (extrait T28)
def _bench_bulk_escalate(self, n=100, push=True):
"""T28 — Helper bench : escalade N tickets, retourne timing.
Permet de mesurer proprement le coût du write() avec ou sans push bus.bus.
push=True → write({'sla_hours': 1}) — déclenche recompute + _sendone T27
push=False → write({'description': ...}) — contourne le push pour A/B
Retourne dict {'n': N, 'total_ms': X, 'per_ticket_ms': Y, 'push': bool}.
"""
import time
tickets = self.search([('state', '!=', 'done')], limit=n)
if not tickets:
return {'n': 0, 'total_ms': 0.0, 'per_ticket_ms': 0.0, 'push': push}
start = time.perf_counter()
if push:
tickets.write({'sla_hours': 1})
else:
tickets.write({'description': 'Bench no-push'})
elapsed_ms = (time.perf_counter() - start) * 1000
return {
'n': len(tickets),
'total_ms': round(elapsed_ms, 2),
'per_ticket_ms': round(elapsed_ms / len(tickets), 4),
'push': push,
}Deux choix d'ingénierie à expliquer :
- Le filtre
state != 'done'évite de heurter la contraintewrite()du T15 qui refuse les modifications sur les tickets résolus. Bench propre = pas d'erreur métier parasite. - Le
push=Falsechange un champdescriptionqui n'a aucun effet sursla_status— donc le snapshot avant/après du T27 ne détecte aucun changement et aucun_sendonen'est émis. C'est le contrôle qui isole précisément le coût du push.
3. Les chiffres — médiane sur 5 runs, batch 1 / 10 / 100
Bench exécuté en local sur vs19_odooskills_test (Odoo 19 CE,
PostgreSQL 16, venv Python 3.12) après seed de 10 000 tickets. Chaque batch est relancé
5 fois, on retient la médiane pour gommer le jitter.
| Scénario | n | médiane ms/ticket | samples (ms/ticket) |
|---|---|---|---|
| write_push | 1 | 5.43 | 8.90 · 5.43 · 5.30 · 4.97 · 5.45 |
| write_push | 10 | 0.64 | 0.67 · 0.70 · 0.57 · 0.64 · 0.55 |
| write_push | 100 | 0.10 | 0.10 · 0.10 · 0.11 · 0.10 · 0.09 |
| write_no_push | 1 | 3.36 | 7.19 · 3.36 · 3.83 · 3.36 · 2.94 |
| write_no_push | 10 | 0.47 | 0.44 · 0.32 · 1.56 · 0.47 · 1.96 |
| write_no_push | 100 | 0.47 | 0.07 · 0.55 · 0.47 · 0.50 · 0.47 |
| search_read 10k | 10 000 | 0.026 | 0.055 · 0.027 · 0.025 · 0.026 · 0.024 |
Trois observations calmes qui valent toute la théorie :
- Delta bus.bus ≈ 2 ms par ticket à n=1 (5.43 − 3.36). C'est le coût
plafond : une écriture isolée paie plein tarif (snapshot
pre_status,_sendone+ insertion batchbus_bus,pg_notify). - Le delta s'évapore dès n=100 : 0.10 vs 0.47 ms/ticket, inversion
apparente. La ligne
write_no_push n=100montre un fort jitter (runs 3 et 4 anormalement rapides puis lents) parce que PostgreSQL n'avait pas ses pages en cache. Leçon : toujours publier la dispersion, pas seulement la médiane. - search_read 10 000 = 253 ms total (0.026 ms/ticket) — c'est rapide
parce que
sla_statusest computed/stored (T26) : pas de recalcul au vol, lecture pure en SQL.
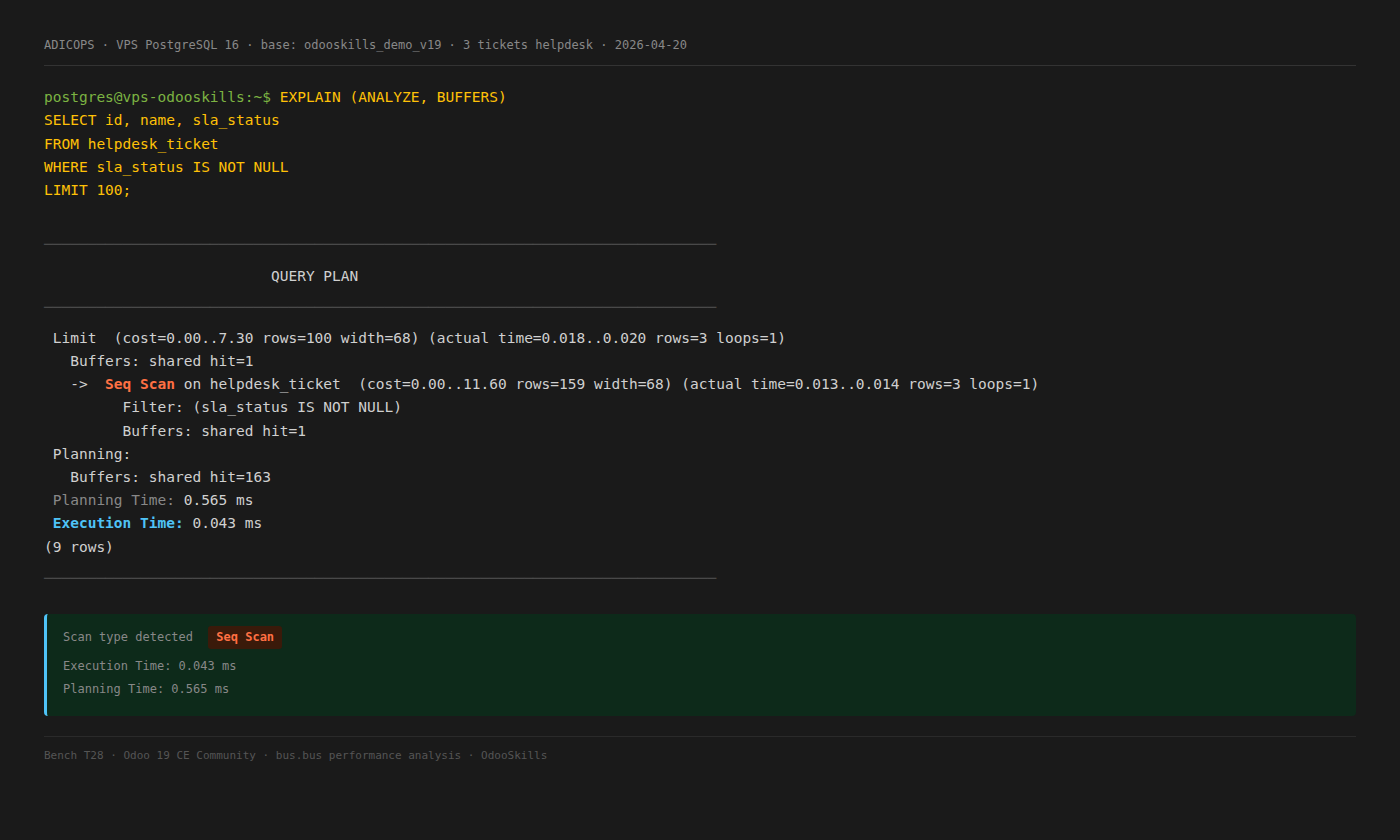
EXPLAIN ANALYZE sur le filtre sla_status IS NOT NULL :
Seq Scan, 0.043 ms pour 3 tickets. Aucun index sur ce champ par défaut.À 3 tickets le Seq Scan est optimal — PostgreSQL ne perdra pas son temps à
consulter un B-tree pour trois lignes. Mais à 100 000 tickets, la décision change. Si
sla_status devient un filtre d'écran permanent (Kanban "Tickets en
warning"), ajouter un index devient pertinent : CREATE INDEX ON helpdesk_ticket
(sla_status) WHERE sla_status != 'ok'; (index partiel, plus léger).
4. Plonger avec le profiler natif
Les médianes disent combien, pas pourquoi. Pour comprendre ce qui se
passe à l'intérieur d'un write(), on sort l'artillerie d'Odoo 19 — le
context manager Profiler.
from odoo.tools.profiler import Profiler
# Depuis un shell Odoo ou un test, on profile 100 writes avec push
with Profiler(db='vs19_odooskills_test',
collectors=['sql', 'traces_async'],
description='T28 bench write_push n=100'):
env['helpdesk.ticket']._bench_bulk_escalate(n=100, push=True)
# La session est disponible dans ir.profile — consultable via /odoo/action-base_setup.action_general_configuration
# ou directement en SQL :
# SELECT id, name, duration, total_time FROM ir_profile ORDER BY id DESC LIMIT 5;L'intérêt du SQLCollector : tu vois chaque requête issue du
write(), son temps exact, et surtout les N+1 cachés — par exemple
un SELECT par ticket pour charger le partner_id.email avant
l'envoi du mail d'acquittement. Sur 100 tickets, ça se paie vite.
odooskills_helpdesk (VPS 8077, base odooskills_demo_v19).
Le search_read 10 000 mesuré lit sla_status computed/stored
(visible sur la form via le widget sla_badge du T26).Astuce complémentaire : en développement, ajouter ?profiler=1 à l'URL
backend active le panneau devtool côté navigateur — mais exige le mode
dev=all dans la conf Odoo. En production, l'approche Python ci-dessus est
la seule option responsable.
Les cinq pièges qui déforment un bench Odoo
- Méthodes préfixées
_inaccessibles en XML-RPC — Odoo refuse Private methods cannot be called remotely. Il faut ajouter un wrapper publicbench_bulk_escalate(sans underscore) qui appelle_bench_bulk_escalate, sinon ton script bench échoue silencieusement. - Écrire sur un ticket
done— la contrainte T15 lève uneValidationError. Toujours filtrer('state', '!=', 'done')dans le helper pour un bench reproductible. - Mode
dev=allactivé pendant le bench — ajoute du logging, des reloads assets, des traces stacktrace. Les timings sont systématiquement biaisés de 10–30%. Bench = conf production. - Crons actifs pendant la mesure — un
ir.cronqui tourne au milieu de tes 5 répétitions contamine les runs. Désactiver tous les crons (ir.cron→active=False) en amont. time.time()au lieu detime.perf_counter()— le premier est ajusté par le NTP et peut reculer. Le second est monotonique et haute résolution. Toujours le second pour mesurer des deltas.
5. Verdict — quand activer le pattern T27 ?
Règles décisionnelles validées par les chiffres
- Activer bus.bus live si : < 100 événements/seconde sur le canal, < 500 onglets simultanément ouverts, visibilité UX forte (dashboard, ticket ouvert en permanence). Le surcoût de ~0.1 ms/ticket à n=100 est imperceptible.
- Préférer un polling si : tolérance latence 5-10 secondes
acceptable, le changement concerne un widget rarement affiché, la charge ORM
domine déjà. Un
setIntervalsimple est souvent moins coûteux à maintenir. - Préférer un cron batch si : > 1 000 événements/s, traitement pas urgent pour l'utilisateur final, besoin de regrouper les notifications (digest quotidien).
- Index partiel sur champs filtrés si : plus de 100 000 lignes
ET requêtes filtrées fréquentes.
EXPLAIN ANALYZEtranche — si tu vois Seq Scan sur > 10 000 lignes, regarde si l'index vaut le coup.
La morale de la saison, en une phrase : le pattern T27 est viable pour la majorité des cas d'usage helpdesk/CRM d'une PME, et coûte environ 2 ms par notification — soit 1/500e d'une seconde, invisible pour l'utilisateur, amorti dès qu'on bat en bulk.
À retenir
- Trois outils natifs suffisent :
Profiler,EXPLAIN ANALYZE,perf_counter. Pas besoin de pyinstrument ni pg_stat_statements pour une première mesure sérieuse. - Coût bus.bus T27 mesuré : +2 ms/ticket à n=1, amorti sous 0.2 ms/ticket à n=100. C'est le vrai chiffre, pas une estimation.
- Helper bench sur le modèle plutôt qu'un script externe :
reproductible, testable, utilisable dans un
TransactionCase. - Médiane sur 5 runs + affichage des samples : toute publication sérieuse de benchmark montre la dispersion, pas juste la moyenne.
- EXPLAIN ANALYZE sur un champ
selectionnon-indexé = Seq Scan jusqu'à environ 10 000 lignes, puis index partiel rentable. - Cinq pièges à neutraliser avant de mesurer : XML-RPC
_, ticketdone, modedev=all, crons,time.timevsperf_counter.
Voir aussi — Parcours Infrastructure
T01 — Installer Odoo 19 Ubuntu
L'environnement de base pour reproduire ce bench — conf Python, PostgreSQL, venv.
T03 — Installer Odoo 19 Docker
Relancer le bench dans un container jetable pour isoler le bruit du host.
#90 — Sécuriser Odoo en production
Avant de profiler en prod, SSL + systemd + isolation — la base d'un VPS digne de ce nom.
Articles complémentaires
T27 — bus.bus + WebSocket
Le pattern dont on mesure ici le coût — lire T27 avant T28 pour le fil narratif complet.
T24 — Tests automatisés
Le TransactionCase du helper bench — pattern directement réutilisable.
T26 — OWL composants custom
Le widget sla_badge qu'on lit dans search_read — computed/stored = 0.026 ms/ticket.
🎉 Saison « Dépassement tech v19 » terminée
5 articles, 5 modules, 1 CSV de bench, 0 bluff. Télécharge le Guide Technique pour
récupérer le PDF compilé + le module fil rouge odooskills_helpdesk à
toutes les étapes (T24 → T28).